


When Scale AI doesn't cut it: doing data labelling in-house
We in-housed our data labelling and it's the best thing we did

At Enhanced Radar, we’ve developed Yeager, a SOTA model that understands air traffic control audio, and we continue to develop other AI models for aviation applications. Due to the industry-specific technical complexity of our data, we could not possibly outsource this labelling effort to a third party and still meet our quality standards, forcing us to label our data in-house.
Looking back, our decision to control our own labelling was vindicated at every step. The iterative process of building our labelling engine was the result of 1:1 relationships with our hundreds of (domain expert) reviewers, thousands of emails, and dozens of internal product updates, that now allow us to label a huge volume of messy data at a high degree of standardization and near-perfect accuracy — all with minimal intervention.
Incentive Alignment
Obvious but necessary: to incentivize productive work, we tie compensation to the number of characters transcribed, and assess financial penalties for failed tests (more on tests below). Penalties are priced such that subpar performance will result in little to no earnings for the labeller.
UI designed for speed
Speed translates to cost savings, so we optimize for it at the expense of aesthetics. The interface presents the user with a single audio clip, pre-transcribed by one of our models.
All text in the text area is forced-uppercase, freeing the user from making judgements on capitalization, or reaching for the shift key.
All buttons in the dashboard are given (and labelled with) a keyboard shortcut, and the critical ones are oversized, color-coded, and placed directly below the text field.

An audio waveform and playhead is shown, allowing the user to quickly replay specific parts of a clip he may have questions about. Clicking on the waveform will cause the clip to start playing even if the audio has been paused.

Subsequent audio clips are pre-fetched, allowing a new clip to load instantly after the previous one is submitted.
Gamification and Positioning
Every effort at gamification has been rewarded beyond our expectations. (Don’t assume that someone who’s intelligent and self-motivated still doesn’t respond to stimuli.)
All of our contractors are skilled and most have well-paying day jobs, resulting in their time on the platform carrying a higher opportunity cost than most data labellers’. For this reason we designed every aspect of the platform to treat the users with respect. We address our labellers as “reviewers,” which more accurately describes the high-skill process they’re tasked with. We also take care to never make a rule, give an instruction, penalize a user, or push a platform update without thoroughly explaining the “why” behind it — doing otherwise would be disrespectful.
To maximize gamification and to give us future flexibility for adjusting our payscale, reviewers earn points which are convertible to dollars at an agreed-upon rate. One point is earned for every character transcribed. For the average clip, a reviewer will earn approximately 50 points, which we add to a running tally at the top of the interface. We animate this number increase using Odometer, and display dollar earnings next to the points tally.

Each reviewer is tested for accuracy at random. For every test passed, the user is shown a shower of confetti; for every failed test, the user is shown a text diff to help them correct their failed test.
The reviewer’s accuracy is shown at the top of the interface, and updates in real-time. To encourage speedy remediation, the accuracy shown is calculated from just their last 200 tests.
New reviewers are given a 1000-point credit to start; this helps them avoid seeing negative points (and negative earnings) in case they fail several tests in their first minutes of using the platform, and increases Day 1 retention.
Reviewers are paid weekly, to tighten the feedback loop between effort and reward.
Labeller Performance Control
Our first challenge was maintaining labeller performance.
Every reviewer is presented with a number of test clips, ranging from 10-30% of the clips they see, based on their accuracy track record. Failing a test will cost a user 600 points, or roughly the equivalent of 15 minutes of work on the platform. A correctly tuned penalty system removes the need for setting reviewer accuracy minimums; poor performers will simply not earn enough money to continue on the platform.
Due to the technical nature of our audio data, each of our labellers is required to have meaningful air navigation experience in U.S. airspace. All labellers are either licensed pilots or controllers (or VATSIM pilots/controllers).
Still, expert reviewers will occasionally disagree in their labelling. To ensure quality, an audio clip ██████ ██████ ██ ██ ███████ █████████ █ ████ █████ ████ ████████ ███████ ███ █ ██ █████ ██ ███████, at which point that clip becomes a “candidate”. From there, this candidate clip is sent to a manager for final review. Managers are reviewers with a track-record for exceptional judgement, who can change the status of a clip from “candidate” to “final”.
Finalized clips are then ready for use in AI training, but are also used as test clips. As each normal audio clip is presented to the user with an AI-generated “pre-transcription,” test clips must be disguised by showing an imperfect transcript for the user to correct. For every test, we use a small LLM to generate a slightly “wrong” transcript to present to the user.
To maintain reviewer trust, we allow users to “dispute” a failed test and provide a one-sentence explanation for their reasoning. This dispute is viewed by a manager, who can choose to accept the dispute, reject it, or classify as ambiguous. For accepted or ambiguous disputes, the reviewer’s point penalty is reversed and that reviewer is notified in their dashboard. Clips where two domain experts can be reasonably expected to disagree on their interpretation are marked as “ambiguous”; these are removed from the test pool, and can be deleted from the training set entirely if the ambiguity risks adding noise to our dataset.
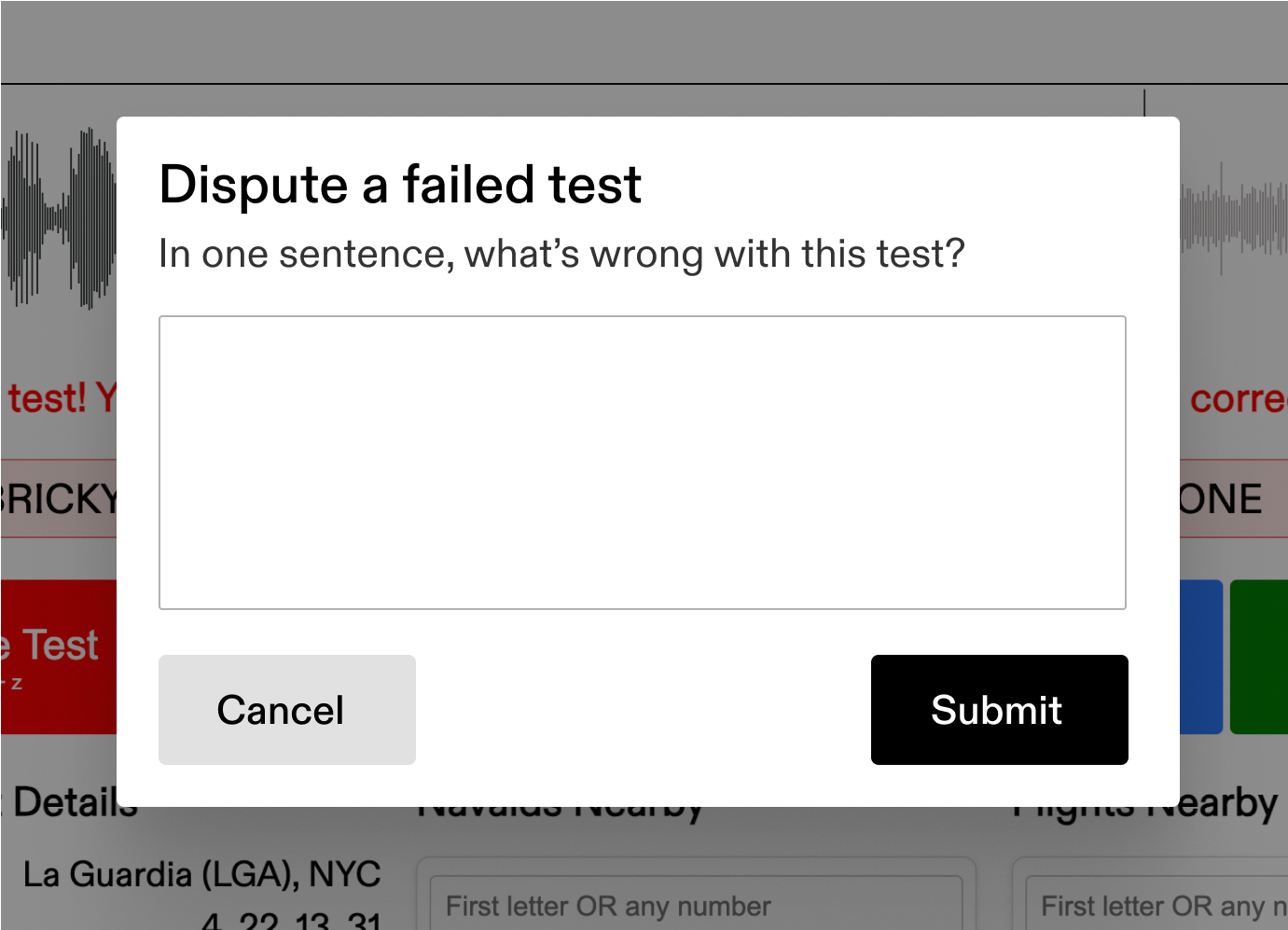
Conveniently, the “dispute a failed test” functionality also doubles as the nth set of eyes on a given audio clip. Disputed clips are sent to a qualified manager for a final decision. As we add new data sources, reviewer disputes give us critical feedback on standardizations to implement; often, a new airport environment introduces a number of rare-but-critical phrases or words that we must standardize or add to our spell-check/grammar-check.
Manager quality is measured independently, on several metrics.
Standardizing Interpretation
Standardization of interpretation of the speech is critical for model performance, and for fairly measuring each reviewer’s accuracy. While our reviewer vetting, training, and guidelines do most of the work, we still customize our UI for this.
Reviewers are unable to submit a transcript containing a known spelling or grammatical error. We use a spell-check customized for aviation communications (an off-the-shelf spell-check would reject “DUYET,” a real navigational fix just southeast of SFO, for example). Similarly, we customize our spell check to accept only one version of words that can be spelled correctly in multiple ways, such as “all right” / “alright,” or “OK” / “okay.”

Reviewers who fail a test are required to fix and re-submit their answer, to reinforce their understanding of our standards.
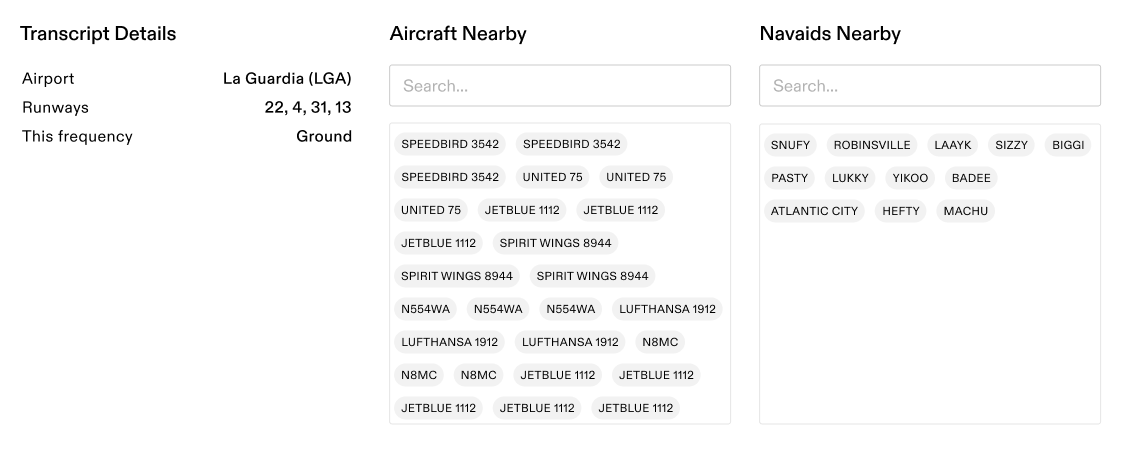
A large percentage of aviation communications reference proper nouns, such as “JetBlue 2313,” “LAAYK” (a navigational fix), or “runway one six right.” Further, many navigational fixes are made-up words whose spelling often can’t be derived from their pronunciation. Callsigns present a similar issue (Air France’s call sign is “AIRFRANS,” for example).
To address this we collect airspace metadata at the time of audio capture, including the callsigns of all nearby aircraft, the names of all nearby navigational aids, and the runway configuration for terminal area audio data. We present this data below the transcript so the reviewer can verify the spelling of these words.
Final thoughts
As we continue to develop the best AI models for aviation command & control, we’re only accelerating our effort in building the things that build the things for us. Recently we’ve built a lot more to improve our labelling and the fidelity of our annotation, but we’ll discuss that a year or two from now.
One final thought: if you’re not a foundational AI research company and you can outsource your data labelling to anonymous gig workers on another continent, do you even have a data advantage? Do you have a Process Power advantage?